22 minutes
Introdução a Índices do PostgreSQL
Para quem é este texto
Este texto é para desenvolvedores que possuem um conhecimento intuitivo do que são índices de banco de dados, mas não necessariamente sabem como eles funcionam internamente, quais são as vantagens e desvantagens associadas aos índices, quais são os tipos de índices fornecidos pelo postgres e como você pode usar alguns de suas opções mais avançadas para torná-las mais otimizadas para seu caso de uso.
Conceitos Básicos
Os índices são objetos especiais de banco de dados projetados principalmente para aumentar a velocidade de acesso aos dados, permitindo que o banco de dados leia menos dados do disco. Eles também podem ser usados para impor restrições como chaves primárias, chaves exclusivas e exclusão. Os índices são importantes para o desempenho, mas não aceleram uma consulta, a menos que ela corresponda às colunas e aos tipos de dados do índice. Além disso, como regra geral, um índice só ajudará se menos de 15-20% da tabela for retornada na consulta; caso contrário, o planejador de consulta, uma parte do postgres usada para determinar como a consulta será ser executado, pode preferir uma varredura sequencial. Na verdade, a realidade é muito mais complexa do que esta regra prática.
O planejador de consultas usa estatísticas e custos predefinidos associados a cada tipo de verificação para realizar seu trabalho. Portanto, se a sua consulta retornar uma grande porcentagem da tabela, considere refatorá-la, usando materialized views, stored procedures ou outras técnicas antes de jogar um índice no problema. Com isso em mente, vamos dar uma olhada mais de perto em como o Postgres armazena seus dados no disco e como os índices ajudam a acelerar a consulta desses dados.
Existem seis tipos de índices disponíveis na instalação padrão do Postgres e mais tipos disponíveis por meio de extensões. Normalmente, eles funcionam mapeando um valor-chave a um TID (tuple id), que é um endereço lógico para que aponta uma ou mais linhas da tabela que contém essa chave.
Como os dados são armazenados em disco
Para entender os índices, é importante primeiro entender como o Postgres armazena os dados da tabela no disco. Cada tabela no Postgres possui um ou mais arquivos correspondentes em disco, dependendo do seu tamanho. Este conjunto de arquivos é chamado de “heap” e é dividido em páginas de 8kb. Todas as linhas da tabela, internamente chamadas de “tuplas”, são salvas nesses arquivos e não possuem uma ordem específica.
O índice é uma estrutura em árvore que liga as colunas dos índices aos localizadores de linhas, também conhecidos como ctid, no heap. Aprofundaremos sobre os detalhes internos do índice mais tarde.
Para ver os arquivos heap, podemos usar algumas tabelas internas do postgres e ver onde eles estão localizados no disco. Primeiro, podemos entrar no psql pela terminal e executar o comando show data_directory para mostrar o diretório que o Postgres usa para armazenar arquivos físicos do banco de dados.
show data_directory;
data_directory
---------------------------------
/opt/homebrew/var/postgresql@16Agora podemos usar o pg_class interno para encontrar o arquivo onde a tabela heap está armazenada:
create table foo (id int, name text);
select oid, datname
from pg_database
where datname = 'my_database';
oid | datname
-------+-------------------------
71122 | my_database
(1 row)select relfilenode from pg_class where relname = 'foo';
relfilenode
-------------
71123Finalmente, podemos verificar o arquivo no disco executando este comando no shell (ls $PGDATA/base/<database_oid>/<table_oid>):
ls -lrt /opt/homebrew/var/postgresql@16/base/71122/71123
-rw------- 1 dlt admin 0 16 Aug 14:20 /opt/homebrew/var/postgresql@16/base/71122/71123O arquivo tem tamanho 0 porque ainda não fizemos nenhum INSERT nesta tabela. Vamos adicionar algumas linhas à nossa tabela:
insert into foo (id, name) values (1, 'Ronaldo');
INSERT 0 1
insert into foo (id, name) values (2, 'Romario');
INSERT 0 1Podemos adicionar o campo ctid à consulta para recuperar o ctid de cada linha. O ctid é um campo interno que contém o endereço da linha no heap. Pense nisso como um ponteiro para a localização da linha no heap. Consiste em uma tupla no formato (m, n), onde m é o id do bloco e n é o deslocamento da tupla. “ctid” significa “id da tupla atual”. Aqui você pode notar que a linha com id um está armazenada na página 0, deslocamento 1.
select ctid, * from foo;
ctid | id | name
-------+----+---------
(0,1) | 1 | Ronaldo
(0,2) | 2 | Romario
(2 rows)Como os índices aceleram o acesso aos dados
Vamos adicionar mais jogadores à tabela para que o total de linhas seja um milhão:
insert into foo (id, name)
select generate_series(3, 1000000), 'Player ' || generate_series(3, 1000000);Depois de adicionar mais linhas à tabela, seu arquivo correspondente terá 30 MB.
ls -lrtah /opt/homebrew/var/postgresql@16/base/71122/71123
-rw------- 1 dlt admin 30M 16 Aug 16:32 /opt/homebrew/var/postgresql@16/base/71122/71133Quando consultamos uma tabela sem índice, o Postgres lê todas as tuplas em cada bloco do heap e aplica um filtro. Por exemplo, vamos analisar o comando abaixo que busca linhas cujo valor da coluna nome seja igual a “Ronaldo” e mostrar como o banco de dados realizou essa busca. Usamos o comando explain (analyse, buffers).
explain (analyze, buffers) select * from foo where name = 'Ronaldo';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..12577.43 rows=1 width=18) (actual time=0.307..264.991 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=97 read=6272
-> Parallel Seq Scan on foo (cost=0.00..11577.33 rows=1 width=18) (actual time=169.520..256.639 rows=0 loops=3)
Filter: (name = 'Ronaldo'::text)
Rows Removed by Filter: 333333
Buffers: shared hit=97 read=6272
Planning Time: 0.143 ms
Execution Time: 265.021 msObserve na saída a linha que começa com “-> Parallel Seq scan on foo”. Esta linha indica que o banco de dados realizou uma pesquisa sequencial e leu todas as linhas da tabela. O tempo de execução desta consulta foi de 265,021ms. Observe também a linha que diz “Buffers: shared hit=97 read=6272”. Isso significa que precisávamos ler 97 páginas da memória e 6.272 páginas do disco.
Agora vamos adicionar um índice na coluna de nome e ver o desempenho da mesma consulta. Estamos usando o comando create index concurrently, porque não queremos bloquear a tabela para escrita.
create index concurrently on foo(name);
CREATE INDEX
explain (analyze, buffers) select * from foo where name = 'Ronaldo';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Index Scan using foo_name_idx on foo (cost=0.42..8.44 rows=1 width=18) (actual time=0.047..0.049 rows=1 loops=1)
Index Cond: (name = 'Ronaldo'::text)
Buffers: shared hit=4
Planning Time: 0.129 ms
Execution Time: 0.077 msAqui vemos que o índice foi utilizado e que neste caso o tempo de execução foi reduzido de 264,21 para 0,074 milissegundos, e o banco de dados só precisou ler 4 páginas!
A redução no tempo de execução acontece porque, agora, em vez de ler todas as linhas da tabela, o banco de dados utiliza o índice. O índice é uma estrutura em árvore que mapeia o valor “Ronaldo” para o(s) ctid(s) das linhas que possuem este valor na coluna name (no nosso exemplo temos apenas uma dessas linhas). O ctid é então usado para localizar rapidamente essas linhas no heap.
Se usarmos \di+ para mostrar os índices em nosso banco de dados, podemos ver que o índice que criamos ocupa 30MB, aproximadamente o mesmo tamanho da tabela foo.
\di+
List of relations
Schema | Name | Type | Owner | Table | Persistence | Access method | Size | Description
--------+--------------+-------+-------+-------+-------------+---------------+-------+-------------
public | foo_name_idx | index | dlt | foo | permanent | btree | 30 MB |
(1 row)Custos associados a índices
É fundamental lembrar que os ganhos de velocidade proporcionados pelos índices vêm acompanhados de custos que precisam ser avaliados cuidadosamente ao decidir onde e como utilizá-los.
Espaço em disco
Os índices são armazenados em uma área separada do heap e ocupam espaço adicional em disco. Quanto mais índices uma tabela tiver, maior será a quantidade de espaço em disco necessária para armazená-los. Isso acarreta custos adicionais de armazenamento para seu banco de dados e para backups, aumenta o tráfego de replicação e aumenta os tempos de recuperação de backup e failover. Tenha em mente que não é incomum que os índices btree sejam maiores que a própria tabela. Aprender sobre índices parciais e índices multicolunas, bem como sobre outros tipos de índices com maior eficiência de espaço, como BRIN, pode ser útil.
Operações de escrita
Além disso, há um custo de manutenção em operações de escrita como UPDATE, INSERT e DELETE. Se um campo que faz parte de um índice for modificado, o índice correspondente precisa ser atualizado, o que pode adicionar sobrecarga significativa ao processo de escrita.
Planejador de queries
O planejador de consultas (também conhecido como otimizador de consultas) é o componente responsável por determinar a melhor estratégia de execução de uma consulta. Com mais índices disponíveis, o planejador de consultas tem mais opções a considerar, o que pode aumentar o tempo necessário para planejamento, especialmente em sistemas com muitas consultas complexas ou onde há muitos índices disponíveis.
Uso de memória
O PostgreSQL mantém uma parte dos dados acessados com frequência e páginas de índice na memória em seus buffers compartilhados, ou “shared buffers”. Quando um índice é usado, as páginas de índice relevantes são cacheadas em shared buffers para acelerar o acesso. Quanto mais índices você tiver e quanto mais eles forem usados, mais memória será necessária para que o cache do índice seja realizado nos shared buffers. Como eles são limitados e também são usados para cachear dados das tabelas e outros índices. Também é bom ter em mente que toda a coluna indexada é copiada em cada nó da Árvore B, pois há um limite na capacidade do tamanho do nó, quanto maior a coluna indexada mais profunda será a árvore.
Outro aspecto do uso de memória é que o PostgreSQL usa memória de trabalho quando executa consultas que envolvem classificação ou varreduras de índice complexas (envolvendo múltiplas colunas ou cobrindo índices). Índices maiores requerem mais memória para essas operações. Além disso, os índices requerem memória para armazenar alguns metadados sobre sua estrutura, nomes de colunas e estatísticas no cache do catálogo do sistema. E, finalmente, os índices requerem memória para operações de manutenção, como operações de aspiração e reindexação.
Tipos de índices
Btree
A Árvore B ou btree, é uma estrutura de dados muito poderosa, presente não apenas no Postgres, mas em quase todos os sistemas de gerenciamento de banco de dados, pois ele é bem genérico e performa bem com vários de dados. Foi inventado por Rudolf Bayer e Edward M.McCreight enquanto trabalhavam na Boeing. Ninguém sabe realmente se o “B” na árvore B significa Bayer, Boeing, balanceado ou O que realmente importa é que nos permite pesquisar elementos na árvore em tempo O(log n). Se você não está familiarizado com a notação Big-O, tudo que você precisa saber é que O(log n) é bastante rápido - são necessárias apenas 20 comparações para encontrar um elemento em um conjunto com 1 milhão de itens. Além disso, pode manter a complexidade de tempo O(log n) para conjuntos de dados maiores que a RAM disponível em um computador. Isso significa que os discos podem ser usados para estender a RAM, graças à sua eficiente implementação de busca de dados em disco. No PostgreSQL, o btree é o tipo de índice mais comum e é o padrão, também é usado para suportar índices internos do sistema. Mesmo um banco de dados vazio possui centenas de índices btree. É o único tipo de índice que pode ser usado para constraints de chave primária e exclusiva.
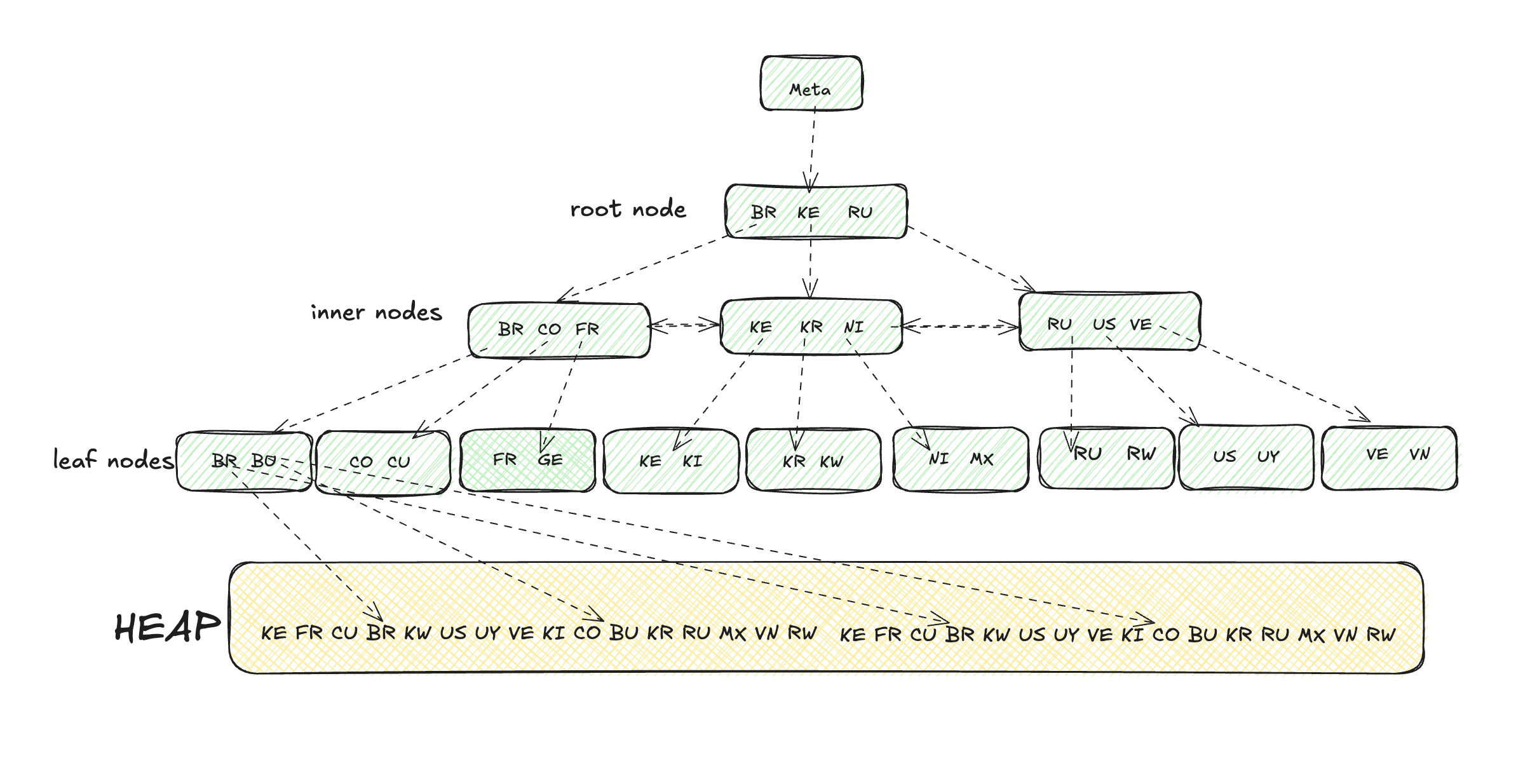
Ao contrário de uma árvore binária, a Árvore B é uma árvore balanceada, ou seja, todos os seus nós finais estão à mesma distância da raiz. Os nós raiz e os nós internos possuem ponteiros para níveis inferiores, e os nós folha possuem as chaves e ponteiros para o heap. As btrees do Postgres também possuem ponteiros para os nós esquerdo e direito para facilitar a varredura para frente e para trás. Os nós podem ter várias chaves e essas chaves são classificadas para que seja fácil caminhar em direções ordenadas e executar operações ORDER BY e JOIN. Os valores são armazenados apenas nos nós folhas, o que torna a árvore mais compacta e facilita um percurso completo dos objetos em uma árvore com apenas uma passagem linear por todos os nós folhas. Abaixo há uma ilustração simplificada de uma árvore B:
Usando múltiplos índices
Podemos usar vários índices para lidar com consultas que usam condições AND e OR em mais de uma coluna. Digamos que temos uma consulta como esta:
select * from users where age = 30 and login_count = 100;Se as colunas age e login_count forem indexadas, o postgres verifica o índice age para todas as páginas com age=30 e cria um mapeamento para as páginas do disco que podem conter linhas com age=30. De forma semelhante, ele constrói outro mapa usando o índice login_count. Em seguida, ele faz um merge dos dois mapas e executa uma varredura na tabela, lendo apenas as páginas que podem conter valores candidatos e selecionando apenas as linhas onde o campo age é igual a 30 e o campo login_count é igual a 100.
Índices compostos
Os índices de múltiplas colunas são uma alternativa para o uso de múltiplos índices. Eles geralmente serão menores e mais rápidos do que usar vários índices, mas também tendem ser menos flexíveis. Isso ocorre porque a ordem das colunas é importante, pois o banco de dados pode procurar um subconjunto das colunas indexadas, desde que sejam as colunas mais à esquerda. Por exemplo, se você tiver um índice na coluna a e outro índice na coluna b, esses índices servirão todas as consultas abaixo:
select * from my_table where a = 42 and b = 420;
select * from my_table where a = 43;
select * from my_table where b = 99;
Um índice composto criado pelo comando create index my_index on my_table(a, b), só é capaz de filtrar se ele também filtra pela coluna a. Exemplo:
select * from my_table where a = 42 and b = 420; -- utiliza index
select * from my_table where a = 42 and b = 420 and c = 4200; -- utiliza index
select * from my_table where a = 42 and c = 4200; -- utiliza index
select * from my_table where a = 42; -- utiliza index
select * from my_table where b = 420; -- não utiliza index
select * from my_table where b = 420 and c = 4200; -- não utiliza indexPor outro lado, apenas as duas primeiras consultas usariam um índice composto colunas em (a, b); Portanto, ao construir índices compostos escolha bem a ordem das colunas para que seu índice possa ser usado pelo maior número de consultas possível.
Skip Scan no PostgreSQL 18
A limitação descrita acima é válida até o PostgreSQL 17. A partir do PostgreSQL 18, o otimizador de consultas conta com uma nova funcionalidade chamada skip scan que permite utilizar um índice composto mesmo quando a consulta não filtra pela coluna mais à esquerda.
O skip scan funciona “pulando” pelos valores distintos da coluna líder do índice. Por exemplo, dado um índice em (a, b) e uma consulta WHERE b = 420, o PostgreSQL 18 pode internamente transformar isso em múltiplas buscas do tipo WHERE a = N AND b = 420 para cada valor distinto de a, e combinar os resultados.
-- Com índice em (a, b), esta consulta agora pode usar o índice no PostgreSQL 18:
select * from my_table where b = 420;Esta otimização é mais eficaz quando a coluna omitida (a coluna líder) tem baixa cardinalidade - ou seja, poucos valores distintos. Casos de uso comuns incluem índices como (país, telefone) ou (fabricante, placa), onde a primeira coluna tem relativamente poucos valores distintos. Em cenários ideais, o tempo de execução pode cair drasticamente - de dezenas de milissegundos para menos de 1 milissegundo.
Vale notar que o skip scan funciona automaticamente, sem necessidade de configuração. O planejador analisa as estatísticas da tabela e decide se aplicar a otimização é a estratégia mais eficiente.
Índices parciais
Os índices parciais permitem que você use uma expressão condicional para controlar qual subconjunto de linhas será indexado, isso pode trazer muitos benefícios:
- seu índice pode ser menor e provavelmente caber na RAM.
- seu índice é mais superficial, então as pesquisas são mais rápidas
- menos sobrecarga para indexar/atualizar/excluir (mas também pode significar mais sobrecarga se a coluna que você está usando para filtrar linhas dentro/fora do índice for atualizada com muita frequência, acionando manutenção constante do índice)
Eles são úteis principalmente em situações em que você não se importa com algumas linhas, ou quando está indexando uma coluna onde a proporção de um valor é muito maior em comparação com outros.
Quando algumas linhas não interessam
Digamos que você tenha uma tabela rules onde as linhas podem ser marcadas como status enabled ou disabled. A grande maioria das linhas estão como disabled, mas nas suas queries você só filtra as linhas que estão enabled. Nesse caso, você pode usar um índice parcial:
create index on rules(status) where status = 'enabled';Quando a distribuição de valores é distorcida
Agora imagine que você está construindo um aplicativo de tarefas e o valor da coluna de status pode ser TODO, DOING e DONE. Suponha que você tenha 1 milhão de linhas e esta seja a distribuição atual de linhas em cada status:
| Rows | Status |
|---|---|
| TODO | 90% |
| DOING | 5% |
| DONE | 5% |
Como o postgres mantém estatísticas sobre a distribuição de valores nas colunas da sua tabela e sabe que a grande maioria das linhas está no status TODO, ele escolheria fazer uma varredura sequencial na tabela tasks quando você tiver status= 'TODO' na cláusula WHERE da sua consulta, mesmo se você tiver um índice em status, deixando a maior parte do índice sem uso e desperdiçando espaço. Neste caso, recomenda-se uma verificação parcial como a abaixo:
create index on tasks(status) where status <> 'TODO';Índices de cobertura
Se você tiver uma consulta que seleciona apenas colunas em um índice, o Postgres terá todas as informações necessárias para a consulta no índice e não precisará buscar páginas no heap para retornar o resultado. Esta otimização é chamada de index-only scan. Para entender como funciona, considere o seguinte cenário:
create table bar (a int, b int, c int);
create index abc_idx on bar(a, b);
/* query 1 */
select a, b from bar;
/* query 2 */
select a, b, c from bar;a e b estão presentes no índice. Na segunda consulta, como c não está no índice, o posgres precisa seguir a referência ao heap para buscar seu valor. Na primeira consulta, permitimos que o postgres fizesse uma varredura somente de índice com a ajuda de um índice de múltiplas colunas, mas também poderíamos obter o mesmo resultado usando um índice de cobertura. A sintaxe para criar um índice de cobertura é semelhante a esta:create index abc_cov_idx on bar(a, b) including c;c “quebraria” a exclusividade do índice.Índices de expressão
Índices de expressão para indexar o resultado de uma expressão ou função, em vez de apenas os valores brutos da coluna. Isso pode ser extremamente útil quando você faz consultas frequentes com base em uma versão transformada dos seus dados. É necessário se você usar uma função como parte de uma cláusula where, como no exemplo abaixo:
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
name TEXT
);
CREATE INDEX idx_name ON customers(name);
SELECT * FROM customers WHERE LOWER(name) = 'john doe';Neste exemplo acima, o Postgres não usará o índice porque ele foi construído na coluna name. Para que funcione, a chave do índice deve chamar a função lower exatamente como é usada na classe where. Para consertar, faça:
CREATE INDEX idx_lower_name ON customers (lower(name));Agora o PostgreSQL pode usar o índice de expressão para encontrar com eficiência as linhas correspondentes.
Os índices de expressão podem ser criados usando vários tipos de expressões:
- Funções integradas: como
lower(),upper(), etc. - Funções definidas pelo usuário: desde que sejam imutáveis.
- Concatenações de strings: como
first_name || ' ' || sobrenome.
Hash
O índice hash difere do B-Tree na estrutura, é muito mais parecido com uma estrutura de dados hashmap presente na maioria das linguagens de programação (por exemplo, dict em Python, array em php, HashMap em java, etc). Em vez de adicionar o valor completo da coluna ao índice, um código hash de 32 bits é derivado dele e adicionado ao hash. Isso torna os índices de hash muito menores do que Árvores B ao indexar dados mais longos, como UUIDs, URLs, etc. Qualquer tipo de dados pode ser indexado com a ajuda de funções de hash do postgres. Existem mais de 50 funções relacionadas ao hash para diferentes tipos de dados, como hashtext e hashrow. Embora lide bem com conflitos de chaves de hash, funciona melhor para distribuição uniforme de valores, e é mais adequado para dados únicos. Nas condições corretas, ele não será apenas menor que os índices btree, mas também será mais rápido para leituras quando comparado a eles. Aqui está o que os documentos oficiais dizem sobre isso:
“Em um índice de árvore B, as pesquisas devem descer pela árvore até que a página folha seja encontrada. Em tabelas com milhões de linhas, essa descida pode aumentar o tempo de acesso aos dados. O equivalente a uma página folha em um índice hash é referido como como uma página de bucket. Em contraste, um índice hash permite acessar as páginas de bucket diretamente, reduzindo potencialmente o tempo de acesso ao índice em tabelas maiores. Essa redução na “E/S lógica” torna-se ainda mais pronunciada em índices/dados maiores que shared_buffers/RAM.”
Quanto às suas limitações, ele suporta apenas operações de igualdade e não será útil se você precisar ordenar pelo campo indexado. Ele também não oferece suporte a índices de várias colunas e verificação de exclusividade. Para uma análise aprofundada de como os índices hash se comportam em relação ao btree, verifique a postagem do blog de Evgeniy Demin no assunto.
BRIN
BRIN significa Block Range Index e seu nome diz muito sobre como ele é implementado. Os nós nos índices BRIN armazenam os valores mínimo e máximo de um intervalo de valores presentes na página referida pelo índice. Isso torna o índice mais compacto e amigável ao cache, mas restringe os casos de uso dele. Se você tiver uma carga de trabalho muito grande, com muitas gravações e poucas exclusões e atualizações. Você pode pensar em um índice BRIN como um otimizador para varreduras sequenciais de grandes quantidades de dados em bancos de dados muito grandes e é uma boa otimização para tentar antes de particionar uma tabela. Para que um índice BRIN funcione bem, a chave do índice deve ser uma coluna que se correlacione fortemente com a localização da linha no heap. Alguns bons casos de uso para BRIN são tabelas somente anexadas e tabelas que armazenam dados de séries temporais.
O BRIN não funcionará bem para tabelas onde as linhas são atualizadas constantemente, devido à natureza do MVCC que duplica as linhas e as armazena em uma parte diferente do heap. Essa duplicação e movimentação da tupla afetam negativamente a correlação e reduzem a eficácia do índice. O uso de extensões como pg_repack ou pg_squeeze não é recomendado para tabelas que usam índices BRIN, pois elas alteram a configuração interna dos dados da tabela e atrapalham a correlação. Além disso, esse índice apresenta perdas no sentido de que os nós folha do índice apontam para páginas que podem conter um valor dentro de um intervalo específico. Por esse motivo, um BRIN é mais útil se você precisar retornar um grande subconjunto de dados, e um btree teria melhor desempenho de leitura para consultas que retornam apenas uma ou poucas linhas. Você pode tornar o índice com mais ou menos perdas ajustando a configuração page_per_range, a compensação será o tamanho do índice.
GIN
O índice invertido generalizado é apropriado para quando você deseja pesquisar um item em dados compostos, como encontrar uma palavra em um bloco de texto, um item em uma matriz ou um objeto em JSON. O GIN é generalizado no sentido de que não precisa saber como irá acelerar a busca por algum item. Em vez disso, há um conjunto de estratégias personalizadas específico para cada tipo de dados. Observe que para indexar um valor JSON ele precisa ser armazenado em uma coluna JSONB. Da mesma forma, se você estiver indexando texto, é melhor armazená-lo como (ou convertê-lo para) tsvector ou usar a extensão pg_trgm.
GiST & SP-GiST
A Árvore de Pesquisa Generalizada e a Árvore de Pesquisa Generalizada Particionada no Espaço são estruturas de árvore que podem ser usadas como modelo base para implementar índices para tipos de dados específicos. Você pode pensar neles como uma estrutura para a construção de índices. O GiST é uma árvore balanceada e o SP-GiST permite o desenvolvimento de estruturas de dados não balanceadas. Eles são úteis para indexar pontos e tipos geométricos, inet, intervalos e vetores de texto. Você pode encontrar uma lista extensa das estratégias integradas enviadas com o postgres na documentação oficial. Se precisar de um índice para ativar a pesquisa de texto completo em seu aplicativo, você terá que escolher entre GIN e GiST. Grosso modo, o GIN é mais rápido para pesquisas, mas é maior e tem maiores custos de construção e manutenção. Portanto, o tipo de índice certo para você dependerá dos requisitos da sua aplicação.
Conclusão
Compreender e usar índices de maneira eficaz é crucial para otimizar o desempenho do banco de dados no PostgreSQL. Embora os índices possam acelerar bastante a execução de consultas e melhorar a eficiência geral, é importante estar atento ao seu impacto nas operações de gravação e no armazenamento. Ao selecionar cuidadosamente os tipos apropriados de índices com base em seus casos de uso específicos, você pode garantir que seu banco de dados PostgreSQL permaneça rápido e eficiente. Espero que este artigo tenha lhe ensinado pelo menos uma ou duas coisas que você não sabia sobre os índices do Postgres, e que você esteja melhor equipado para lidar com diferentes cenários envolvendo bancos de dados de agora em diante.